로컬 LLM을 실행하고 싶은데 어떤 모델이 내 컴퓨터에서 돌아갈지 모르겠다. 8GB RAM에 Llama 3.1 70B를 돌리려다 실패한 경험이 있을 것이다. LLMFit은 이 문제를 한 번에 해결한다. 시스템 사양을 자동으로 분석하고, 실행 가능한 모델만 골라서 보여준다.
“Hundreds of models & providers. One command to find what runs on your hardware.” — 14,000개 이상의 GitHub 스타가 증명하는 실용적인 도구다.
왜 필요한가
로컬 LLM 선택은 복잡하다:
- 모델이 너무 많음: Hugging Face, Ollama 라이브러리, 각종 양자화 버전 — 무엇을 선택해야 할지 모름
- 하드웨어 파악 어려워: 내 GPU가 몇 GB인지, CUDA 버전은 맞는지, VRAM이 충분한지
- 메모리 계산 복잡: Q4 양자화면 얼마나 필요하지? MoE는 활성 전문가만 계산하나?
- 실패 후 재시도 비용: 10GB 모델 다운로드 후 “out of memory” 에러 — 시간 낭비
LLMFit은 이 모든 것을 자동화한다. 한 번의 명령으로.

핵심 기능
1. 자동 하드웨어 감지
LLMFit은 시스템의 모든 가속기를 자동으로 인식한다:
| 하드웨어 | 감지 방법 |
|---|---|
| NVIDIA GPU | nvidia-smi — VRAM, CUDA 코어, 대역폭 |
| AMD GPU | rocm-smi — ROCm 지원 GPU |
| Intel Arc | sysfs — XMX 엔진 정보 |
| Apple Silicon | system_profiler — Unified Memory |
| Ascend NPU | npu-smi — Huawei AI 가속기 |
RAM, CPU 코어, 메모리 대역폭까지 분석해서 정확한 추정치를 제공한다.
2. 다차원 스코어링
단순히 “실행 가능/불가능”이 아니다. LLMFit은 4가지 차원에서 모델을 평가한다:
| 차원 | 평가 기준 |
|---|---|
| Quality | 파라미터 수, 모델 패밀리, 양자화 품질 |
| Speed | tok/s 추정 (하드웨어 대역폭 기반) |
| Fit | 메모리 효율 50-80% 타겟 — 너무 빡빡하면 스왑 발생 |
| Context | 지원 컨텍스트 윈도우 크기 |
이렇게 하면 “실행은 되지만 느린” 모델과 “빠르고 품질 좋은” 모델을 구분할 수 있다.
3. MoE 아키텍처 지원
Mixture of Experts 모델은 특별한 계산이 필요하다:
- Mixtral 8x7B: 총 47B 파라미터지만, 추론 시 2개 전문가만 활성 → 실제 메모리는 ~13B 수준
- DeepSeek-V2/V3: 236B 파라미터, 활성 21B — 일반 236B 모델과 완전히 다른 요구사항
LLMFit은 이를 자동으로 계산한다. 총 파라미터가 아닌 활성 파라미터 기준으로 메모리를 추정한다.
4. 동적 양자화 선택
| 양자화 | 용도 | 메모리 절감 |
|---|---|---|
| Q8_0 | 최고 품질 | ~25% |
| Q6_K | 균형 | ~30% |
| Q4_K_M | 추천 | ~40% |
| Q3_K_M | 절약 | ~50% |
| Q2_K | 극한 절약 | ~60% |
LLMFit은 하드웨어에 따라 최적의 양자화 레벨을 자동으로 추천한다. 16GB RAM이라면 Q4_K_M, 8GB라면 Q2_K를 제안하는 식이다.
5. 속도 추정 공식
tok/s는 이렇게 계산한다:
tok/s = (bandwidth_GB_s / model_size_GB) × 0.550.55는 실제 측정값에서 도출한 효율 계수다. 이론치가 아닌 현실적인 속도를 제공한다.
예시:
- RTX 4090 (1008 GB/s 대역폭) + Llama 3.1 8B Q4 (~5GB)
- = (1008 / 5) × 0.55 ≈ 110 tok/s
인터랙티브 TUI
터미널에서 바로 모델을 탐색할 수 있다:
$ llmfit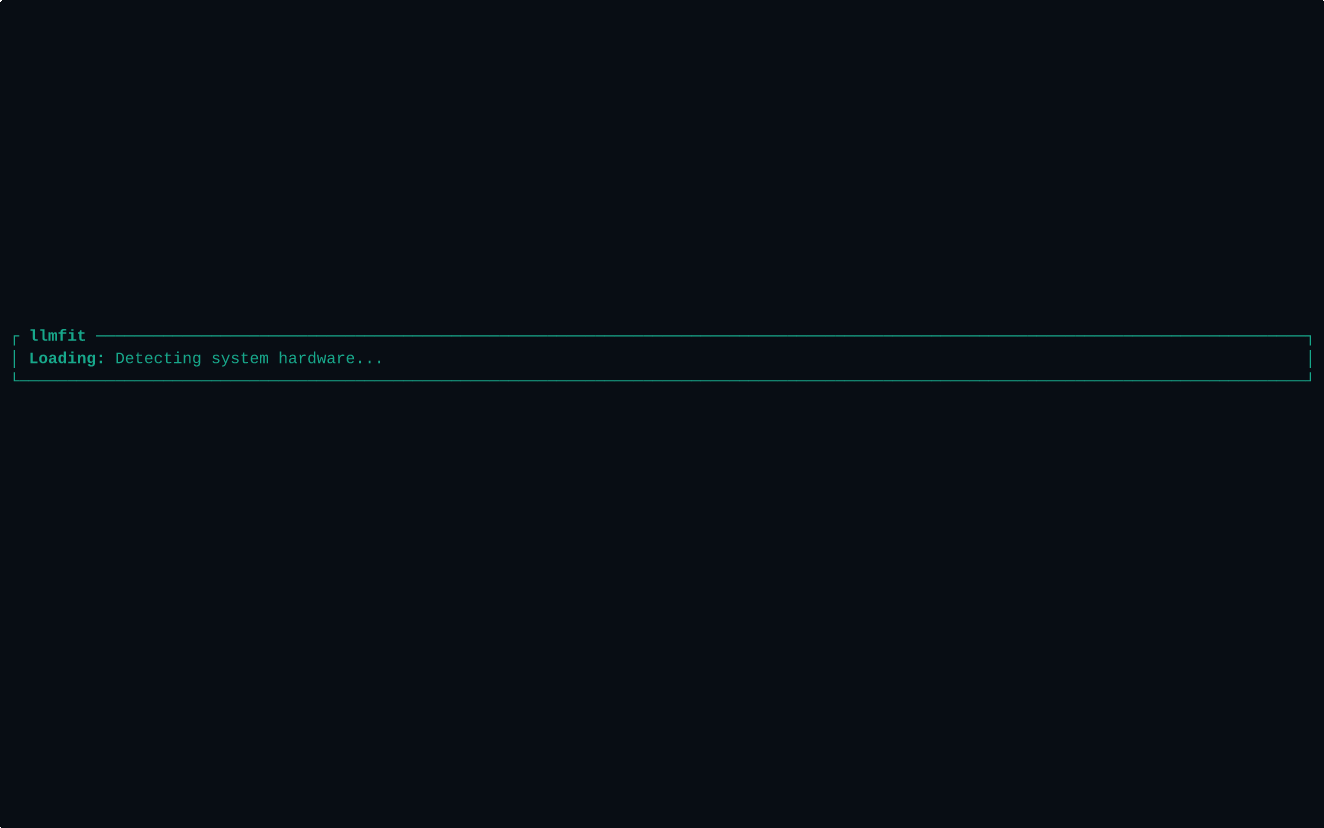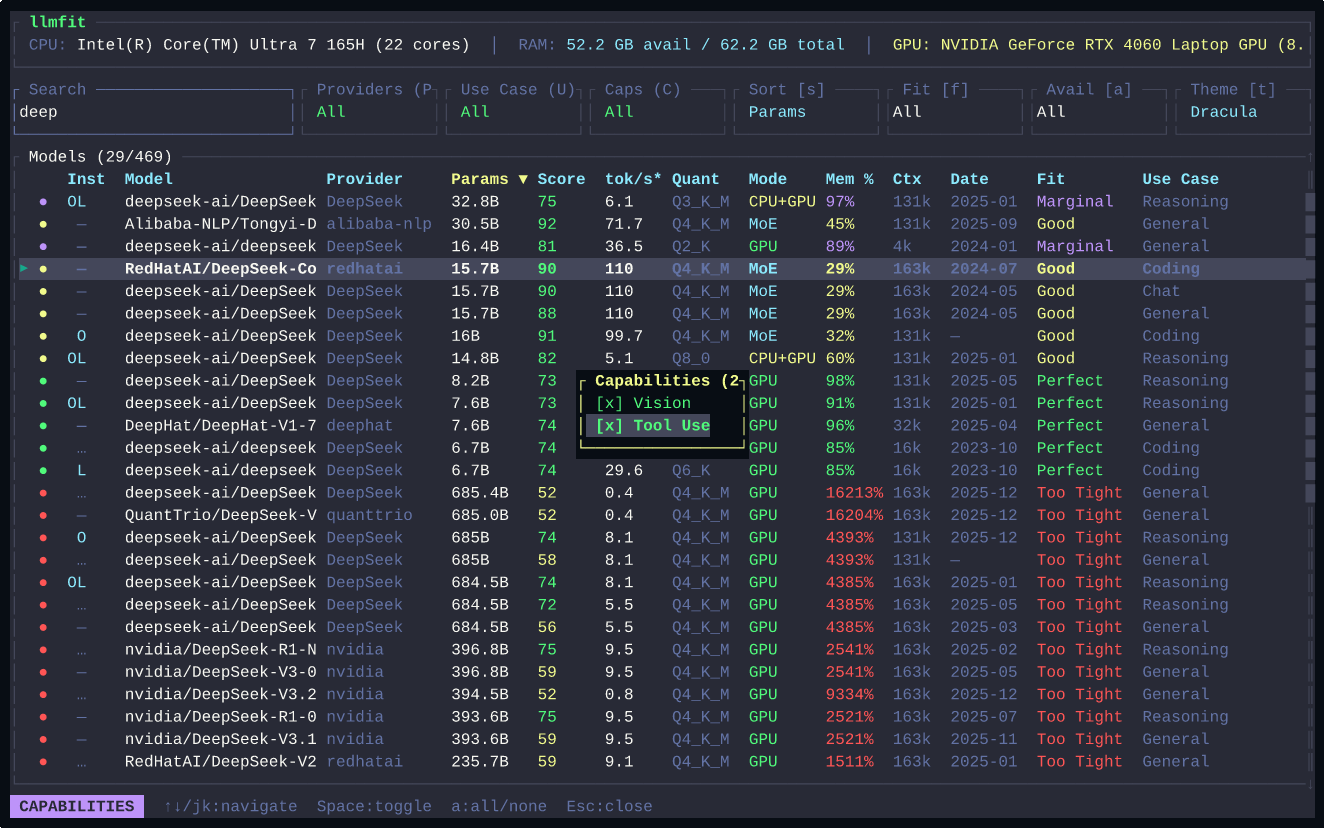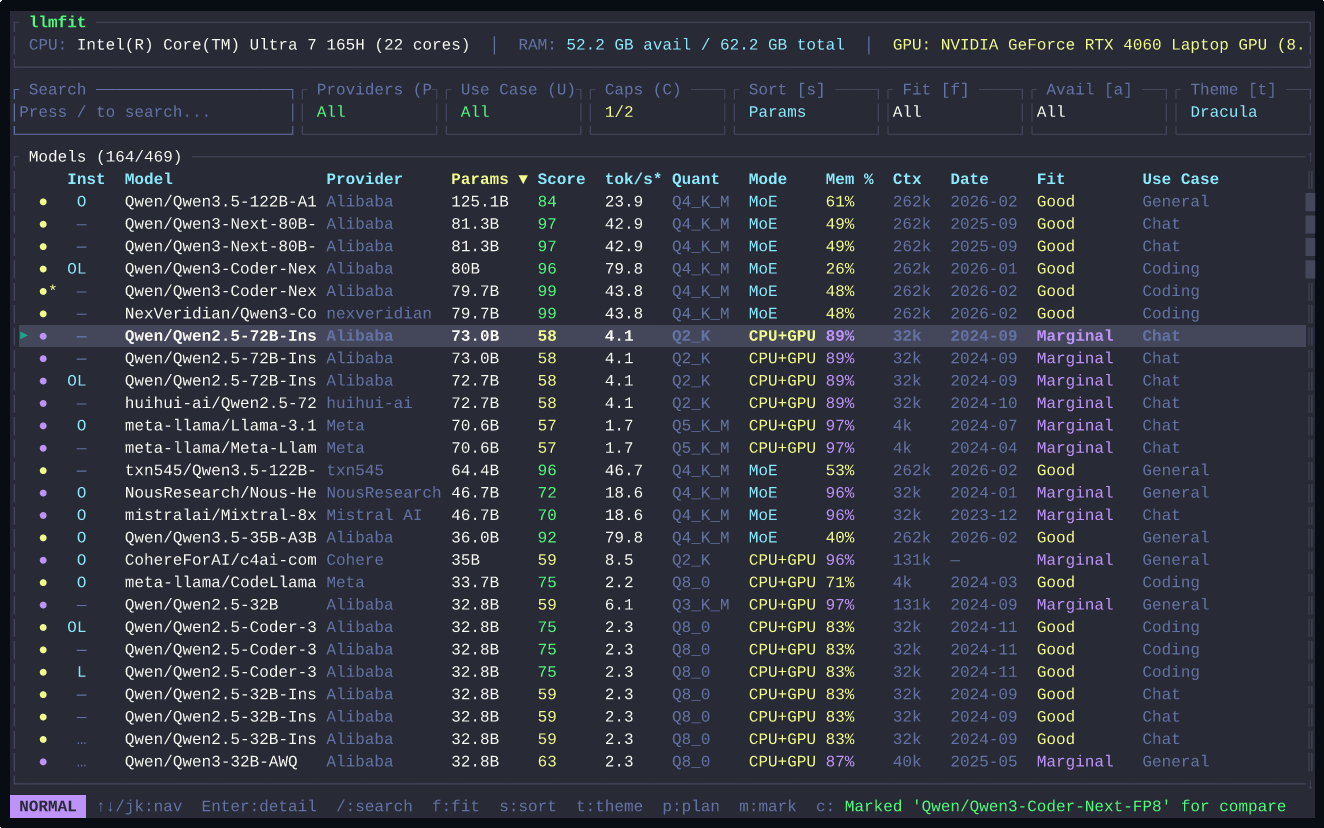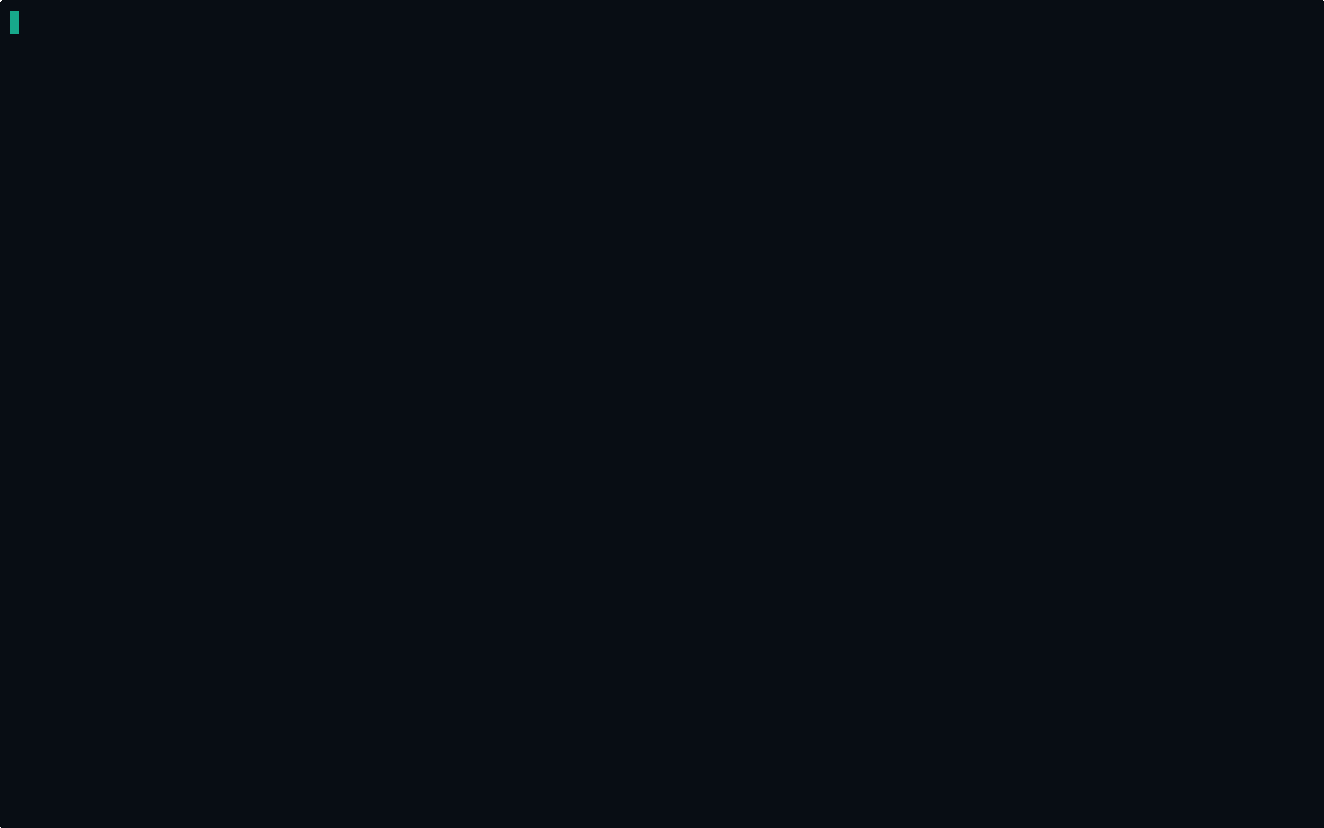
지원 기능
| 기능 | 설명 |
|---|---|
| 검색 | 모델 이름, 패밀리, 태그로 필터 |
| 정렬 | 품질, 속도, 메모리 기준 |
| 필터 | 실행 가능한 모델만 표시 |
| 다운로드 | 선택 시 Ollama로 자동 다운로드 |
Plan Mode (p 키)
“역발상” 기능이다. 원하는 작업을 입력하면 필요한 하드웨어를 역추정한다:
[Plan Mode]
어떤 작업을 하고 싶으신가요? 코드 생성, 128K 컨텍스트
추천 하드웨어:
- RAM: 32GB 이상
- GPU: 16GB VRAM (또는 24GB 권장)
- 추천 모델: Qwen 2.5 Coder 32B Q4_K_M업그레이드 계획을 세울 때 유용하다.
6가지 컬러 테마
개인 취향도 존중한다:
| 테마 | 분위기 |
|---|---|
| Default | 깔끔한 다크 모드 |
| Dracula | 보라빛 하이라이팅 |
| Solarized | 고전 컬러 스킴 |
| Nord | 차가운 블루톤 |
| Monokai | 노란 키워드 강조 |
| Gruvbox | 레트로 따뜻한 톤 |
--theme 옵션 또는 설정 파일에서 변경한다.
REST API 서버 모드
자동화나 다른 도구와 통합할 때 유용하다:
$ llmfit serve
Server running on http://localhost:8080API 엔드포인트
# 하드웨어 정보
GET /api/hardware
# 추천 모델 목록
GET /api/recommend?minQuality=0.8&minSpeed=20
# 특정 모델 상세
GET /api/models/llama3.1:8b
# Plan Mode
POST /api/plan
{
"task": "코드 생성",
"context": "64K"
}OpenClaw 스킬이나 CI/CD 파이프라인에서 활용할 수 있다.
로컬 런타임 프로바이더
LLMFit은 모델 추천만 하는 게 아니다. 바로 실행까지 연결한다:
| 런타임 | 특징 |
|---|---|
| Ollama | 가장 인기, 간편한 CLI |
| llama.cpp | C++ 기반, 최고 호환성 |
| MLX | Apple Silicon 최적화 |
추천 모델을 선택하면 해당 런타임으로 다운로드 명령어를 바로 제공한다:
이 모델을 다운로드하시겠습니까?
ollama pull llama3.1:8b-q4_K_MOpenClaw 스킬 통합
OpenClaw 사용자라면 더 강력하게 활용할 수 있다:
# OpenClaw에서 바로 호출
/skill llmfit
# 현재 하드웨어 기준 추천 모델 표시
# 선택 시 자동 다운로드 및 설정에이전트가 스스로 하드웨어를 분석하고 적합한 모델을 선택하는 자동화가 가능하다.
기술적 딥다이브
Rust로 작성됨
성능과 안정성을 위해 Rust를 선택했다:
- 빠른 시작: 밀리초 단위 실행
- 메모리 안전: 시스템 정보 수집 시 크래시 없음
- 크로스 플랫폼: macOS, Linux, Windows 지원
모델 데이터베이스
Hugging Face, Ollama 라이브러리, Ollama Official을 통합한 메타데이터를 사용한다:
{
"name": "llama3.1:8b",
"family": "llama",
"parameters": "8B",
"quantizations": ["Q4_K_M", "Q5_K_M", "Q8_0"],
"context": 131072,
"moe": false
}주기적으로 업데이트되며 로컬 캐시를 사용해 오프라인에서도 동작한다.
메모리 추정 알고리즘
required_memory = parameters × bytes_per_param × overhead
where:
bytes_per_param = {
Q8_0: 1.0,
Q6_K: 0.75,
Q4_K_M: 0.5,
Q3_K_M: 0.375,
Q2_K: 0.25
}
overhead = 1.1 // 10% 컨텍스트 버퍼MoE의 경우 활성 전문가 비율을 추가로 적용한다.
빠른 시작
macOS
brew install llmfitWindows
scoop install llmfitLinux
curl -fsSL https://llmfit.axjns.dev/install.sh | sh실행
# 인터랙티브 모드
llmfit
# 빠른 추천
llmfit recommend --top 5
# 특정 모델 정보
llmfit info llama3.1:70b
# API 서버
llmfit serve --port 8080LLMFit vs 다른 도구
| 기능 | LLMFit | Ollama | LM Studio | Hugging Face |
|---|---|---|---|---|
| 하드웨어 감지 | ✅ 자동 | ❌ | ✅ | ❌ |
| MoE 계산 | ✅ | ❌ | ❌ | ❌ |
| 속도 추정 | ✅ | ❌ | ⚠️ | ❌ |
| 양자화 추천 | ✅ | ❌ | ⚠️ | ❌ |
| TUI | ✅ | ❌ | ✅ GUI | ❌ |
| API 서버 | ✅ | ✅ | ❌ | ❌ |
| CLI 우선 | ✅ | ✅ | ❌ | ❌ |
언제 LLMFit을 쓸까
추천
- 로컬 LLM 처음 시작 — 어떤 모델을 써야 할지 모름
- 하드웨어 업그레이드 계획 — 어떤 사양이 필요한지 확인
- 다양한 모델 테스트 — 빠르게 실행 가능한 모델 탐색
- CI/CD 통합 — 자동화 파이프라인에서 모델 선택
- 에이전트 개발 — OpenClaw 스킬로 자동 모델 선택
비추천
- 이미 특정 모델 고정 사용 — 굳이 필요 없음
- 클라우드 LLM만 사용 — 로컬 실행 안 함
- GUI 선호 — TUI가 불편하면 LM Studio 추천
마치며: 하드웨어 인식 AI 시대의 필수 도구
LLMFit은 단순한 모델 검색 도구가 아니다. 하드웨어와 AI 모델 사이의 번역기다.
핵심 가치 정리
- 자동 감지 — 시스템 사양을 알 필요 없음
- 정확한 추정 — MoE, 양자화, 속도까지 계산
- 바로 실행 — Ollama, llama.cpp로 즉시 연결
- 개발자 친화적 — CLI, API, 스킬 통합
- 오픈소스 — 14,000+ 스타, 활발한 개발
로컬 LLM의 진입 장벽을 낮추는 도구다. “내 컴퓨터에서 뭘 돌릴 수 있지?”라는 질문에 대한 명확한 답을 준다.
빠른 시작
# 설치
brew install llmfit # macOS
# 실행
llmfit
# 추천받기
llmfit recommend --top 5그리고 Enter. 그게 다다.
🔗 관련 정보
- GitHub: https://github.com/axjns/llmfit
- 웹사이트: https://llmfit.axjns.dev
- 설치 스크립트: https://llmfit.axjns.dev/install.sh
- 라이선스: MIT