![]()
14,000개가 넘는 GitHub 스타를 받은 프로젝트가 있다. 70B 파라미터의 거대 언어 모델을 단일 4GB GPU에서 돌린다고 주장한다. 양자화도, 증류도, 가지치기도 없이 말이다.
처음 들었을 때 믿기지 않았다. 보통 70B 모델은 최소 40GB 이상의 VRAM이 필요하니까. 하지만 AirLLM은 이를 가능하게 만들었다. 그 비밀은 무엇일까?
문제: VRAM의 벽
LLM 추론의 가장 큰 장벽은 메모리다.
- 7B 모델: FP16으로 약 14GB VRAM 필요
- 70B 모델: FP16으로 약 140GB VRAM 필요
- 405B 모델: FP16으로 약 810GB VRAM 필요
이런 요구사항 때문에 개발자들은 보통 두 가지 선택지를 갖는다:
- 클라우드 API 사용 - 비용이 지속적으로 발생
- 양자화 모델 사용 - 품질 저하 감수
AirLLM은 제3의 길을 제시한다.
AirLLM의 핵심: 레이어 단위 로딩
AirLLM의 핵심 아이디어는 놀랍게도 단순하다.
전체 모델을 VRAM에 올리지 않는다.
대신 모델을 레이어별로 분리해 디스크에 저장하고, 추론 시 현재 필요한 레이어만 VRAM에 로드한다. 하나의 레이어 연산이 끝나면 해당 레이어를 VRAM에서 내리고, 다음 레이어를 로드하는 방식이다.
전통적 방식: [Layer 1-80] 모두 VRAM 상주 → 140GB 필요
AirLLM 방식: [Layer N]만 VRAM 상주 → 약 2GB 필요이 접근법의 장점:
- VRAM 요구량 획기적 감소: 70B 모델을 4GB로
- 모델 품질 보존: 양자화로 인한 정확도 손실 없음
- 범용성: 기존 HuggingFace 모델 그대로 사용
실제 사용법
AirLLM의 사용법은 기존 transformers와 거의 동일하다.
from airllm import AutoModel
MAX_LENGTH = 128
# HuggingFace 모델 ID 또는 로컬 경로
model = AutoModel.from_pretrained("garage-bAInd/Platypus2-70B-instruct")
input_text = ['What is the capital of United States?']
input_tokens = model.tokenizer(
input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False
)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True
)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)설치도 간단하다:
pip install airllm첫 실행 시 원본 모델을 레이어별로 분리해 저장하는 과정이 필요하다. 충분한 디스크 공간을 확보하자.
속도 개선: 3배 빠른 압축 모드
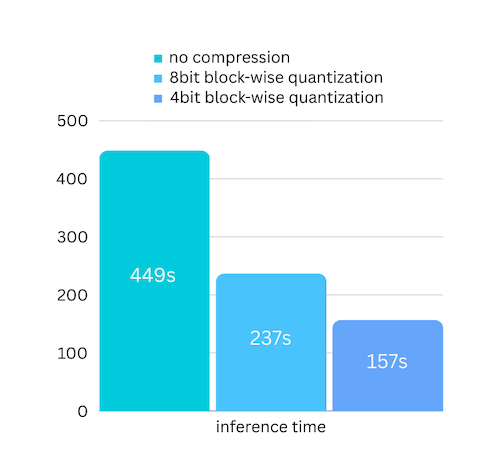
기본적으로 레이어 단위 로딩은 속도를 희생한다. 디스크 I/O가 병목이 되기 때문이다.
AirLLM은 이를 개선하기 위해 블록 단위 양자화 기반 압축을 도입했다. 최대 3배의 속도 향상을 제공하며, 정확도 손실은 거의 무시할 수 있는 수준이라고 한다.
model = AutoModel.from_pretrained(
"garage-bAInd/Platypus2-70B-instruct",
compression='4bit' # 또는 '8bit'
)이 압축이 특이한 점은 가중치만 양자화한다는 것이다. 일반적인 양자화는 가중치와 활성화를 모두 양자화해야 속도 이득이 있는데, AirLLM의 경우 병목이 디스크 로딩에 있어 가중치만 줄여도 충분하다.
지원 모델
AirLLM은 다양한 모델을 지원한다:
| 모델 | VRAM 요구량 |
|---|---|
| Llama2/3 70B | 4GB |
| Llama3.1 405B | 8GB |
| Qwen/Qwen2.5 | 4GB |
| ChatGLM | 4GB |
| Baichuan | 4GB |
| Mistral | 4GB |
| InternLM | 4GB |
MacOS(Apple Silicon)도 지원한다. MLX 백엔드를 통해 M1/M2/M3 맥에서도 70B 모델을 실행할 수 있다.
트레이드오프: 무엇을 희생하는가?
AirLLM이 마법은 아니다. 분명한 트레이드오프가 존재한다.
속도
레이어를 매번 로드해야 하므로 전통적 방식보다 느리다. 초당 토큰 생성 속도가 상당히 떨어진다.
디스크 공간
모델을 레이어별로 분리해 저장하므로 추가 디스크 공간이 필요하다. delete_original=True 옵션으로 원본을 삭제해 공간을 절약할 수 있다.
적합한 사용 사례
- 배치 처리, 오프라인 추론
- 프로토타이핑, 실험
- 실시간 응답이 중요하지 않은 경우
실시간 챗봇 서비스에는 적합하지 않다. 하지만 “한 번 돌려보고 싶은데 A100이 없다”는 상황에서는 완벽한 솔루션이다.
프리페칭으로 속도 개선
AirLLM은 프리페칭을 통해 I/O와 연산을 오버랩한다:
model = AutoModel.from_pretrained(
"garage-bAInd/Platypus2-70B-instruct",
prefetching=True # 기본값
)현재 레이어 연산 중 다음 레이어를 미리 로드하는 방식으로 약 10% 속도 개선 효과가 있다.
마치며: 민주화된 LLM
AirLLM이 의미있는 이유는 단순히 “적은 메모리로 큰 모델을 돌린다”가 아니다.
거대 모델에 대한 접근성을 민주화한다는 점이다.
클라우드 비용을 낼 수 없는 학생, 스타트업, 개인 개발자들도 70B, 심지어 405B 모델을 직접 실험해볼 수 있게 되었다. 물론 느리지만, 돌려볼 수 있다는 것 자체가 큰 변화다.
오픈소스 LLM 생태계가 성장할수록 AirLLM 같은 도구의 가치는 더 커질 것이다. 4GB GPU로 70B를 돌리는 시대가 왔다. 다음은 무엇일까?
관련 정보
- GitHub: https://github.com/lyogavin/airllm
- PyPI: https://pypi.org/project/airllm/
- Discord: https://discord.gg/2xffU5sn
- 창작자 블로그: https://gavinliblog.com