‘397B 파라미터’ 모델을 노트북에서 돌린다.
대부분은 여기서 끝납니다. “그런 건 불가능해” 혹은 “품질이 깨지거나, 속도가 안 나올 텐데” 같은 반응이 자연스럽죠. 그런데 Flash‑MoE는 이걸 “프레임워크 없이(C/Objective‑C/Metal만), SSD에서 전문가(expert)를 스트리밍하며, 도구 호출(tool calling)까지 가능한 품질로” 실제로 밀어붙인 프로젝트입니다.
이 글은 Flash‑MoE가 무엇을 했는지(요약)보다, “어떤 제약을 인정하고 어떤 트레이드오프를 선택했는지(설계)”를 중심으로 정리합니다.
1) Flash‑MoE가 겨냥한 문제: ‘거대 MoE’를 로컬에 올리는 순간 생기는 병목
Flash‑MoE는 Qwen3.5‑397B‑A17B 같은 초대형 Mixture‑of‑Experts(MoE) 모델을 대상으로 합니다.
MoE의 핵심은 “토큰마다 일부 전문가만 활성화(K‑of‑N)”된다는 점입니다. 즉, 전체 파라미터가 397B여도 매 토큰에 실제로 쓰는 전문가 가중치는 일부(K개)뿐입니다.
하지만 ‘일부만 쓴다’가 곧바로 ‘메모리 적게 든다’는 뜻은 아닙니다.
- 전문가 가중치를 전부 RAM/VRAM에 올려두면, 용량이 먼저 터집니다.
- 그렇다고 매 토큰마다 디스크에서 읽어오면, I/O가 병목입니다.
- 애플 실리콘처럼 통합 메모리(unified memory) 구조에서는, GPU와 SSD DMA가 같은 메모리 컨트롤러를 공유해 “겉으로 보기엔 겹칠 수 있을 것 같은 일(SSD 읽기 + GPU 연산)”이 실제로는 서로를 방해할 수 있습니다.
Flash‑MoE는 이 현실을 정면으로 받아들입니다.
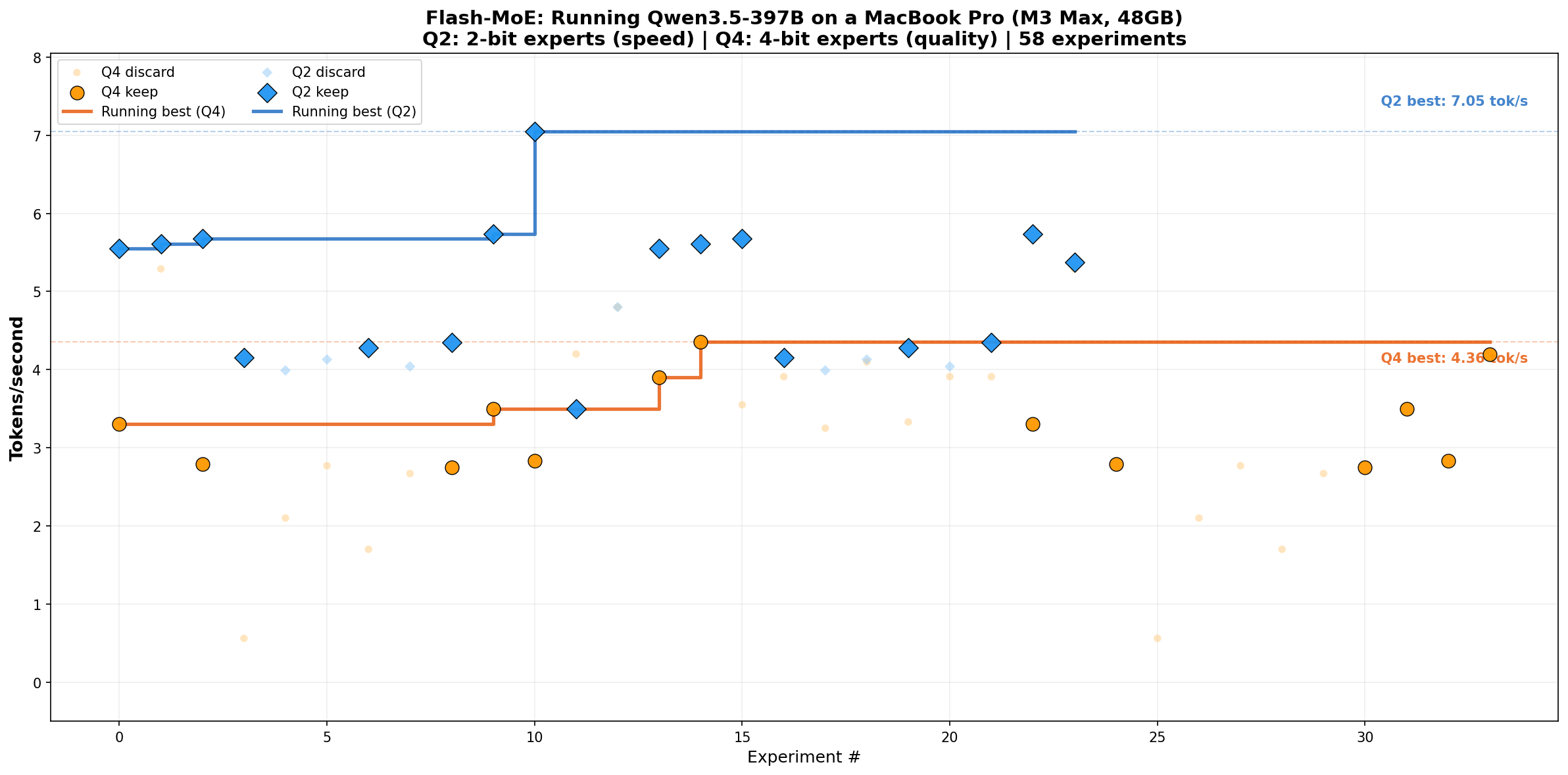
2) 결과(README 기준): ‘4‑bit + 도구 호출’이라는 현실적인 타협점
프로젝트가 공개한 표의 요지는 명확합니다.
- 4‑bit 전문가 + 최적화 커널(FMA): 약 4.36 tok/s, 품질 “Excellent”, tool calling 가능, 디스크 약 209GB
- 2‑bit는 더 빠르지만(5~7 tok/s), JSON 출력이 깨져 도구 호출이 불안정하다고 명시합니다.
왜 2‑bit에서 JSON이 깨지냐는 건 여러 요인이 있을 수 있지만(양자화 오차, 디코딩의 불안정성, 토크나이저/샘플링 설정, 로그릿 스케일 등), 중요한 건 “도구 호출이 목표인 ‘프로덕션’ 구성은 4‑bit”라고 스스로 결론 내렸다는 점입니다.
3) Flash‑MoE의 설계 핵심 1: SSD에서 전문가를 ‘필요할 때만’ 스트리밍
Flash‑MoE의 가장 큰 아이디어는 다음 한 줄로 요약됩니다.
“MoE는 토큰마다 K개 전문가만 쓰니까, 그 K개만 SSD에서 읽어오자.”
README에 따르면:
- 4‑bit 설정에서 전문가 가중치가 디스크에 약 209GB
- 레이어당 전문가 수가 매우 많고(예: 512), 그중 K=4만 활성화
- 활성화된 전문가만
pread()로 병렬 읽기
여기서 ‘당연한 얘기’처럼 보이지만, 실제 구현은 까다롭습니다.
- 어떤 레이어에서 어떤 전문가가 필요할지 CPU에서 라우팅을 먼저 계산해야 함
- 그 결과에 맞춰 동기적으로 SSD에서 읽어와야 함
- 그리고 읽어온 데이터를 GPU(Metal)에서 바로 쓰게 파이프라인을 구성해야 함
4) 설계 핵심 2: “Trust the OS” — 사용자 공간 캐시를 버리고 페이지 캐시에 맡기기
이 프로젝트에서 가장 인상적인 문장 중 하나가 이겁니다.
“커스텀 캐시를 만들지 말고 OS 페이지 캐시를 믿어라.”
직감적으로는 “전문가 캐시를 직접 만들면 더 빠르지 않을까?” 싶지만, Flash‑MoE는 여러 캐싱 시도를 했고(README의 ‘Discarded’ 표), 결과적으로:
- Metal LRU 같은 커스텀 캐시를 유지하는 비용
- GPU 메모리 압박
- 압축/해제 오버헤드
- 잘못된 예측/프리패치로 인한 캐시 오염
…등이 실제 성능을 갉아먹었다고 정리합니다.
이 결론은 “똑똑한 캐시를 만들겠다”는 욕망을 꺾고, 운영체제가 이미 최적화해 둔 페이지 캐시를 그냥 활용한다는 의미입니다. 로컬 추론에서 ‘현실적으로 버틸 수 있는 복잡도’를 선택한 셈이죠.
5) 설계 핵심 3: Metal 커널을 ‘계산식’ 수준에서 손으로 바꿔서 12%를 얻기
Flash‑MoE는 4‑bit 디퀀트(dequant) 매트벡(matvec)의 내부 수식을 재배열해, FMA(fused multiply-add) 유닛을 더 잘 쓰는 형태로 만들었다고 설명합니다.
README의 요약은:
- 원래 형태:
(nibble * scale + bias) * x - 재배열:
fma(nibble, scale*x, bias*x) scale*x,bias*x를 미리 계산해 두면 FMA로 디퀀트+곱을 한 번에 처리- 결과: 약 12% 속도 향상
이건 “큰 그림의 아키텍처”가 아니라 “핫 루프의 수식 재배치”인데도 성능이 체감될 정도로 중요하다는 걸 보여줍니다. 특히 애플 실리콘 GPU에서 대역폭/명령 파이프가 포화되는 구간에서는 이런 미세 튜닝이 크게 먹히기도 합니다.
6) 통합 메모리의 ‘불편한 진실’: SSD DMA와 GPU가 같은 목을 쓴다
Flash‑MoE는 애플 실리콘에서 “SSD DMA와 GPU 연산을 겹쳐서 이득 보기 어렵다”고 못 박습니다.
대략 이런 논리입니다.
- GPU 디퀀트 커널이 이미 메모리 대역폭을 거의 포화(예: 400GiB/s대)
- SSD에서 읽어오는 DMA가 같은 메모리 컨트롤러를 건드리면
- 둘이 ‘동시에’ 돌아가는 게 아니라 서로 latency spike를 유발
그래서 프로젝트는 “GPU → SSD → GPU” 같은 직렬 파이프라인이 하드웨어적으로 최적이라고 정리합니다.
이 대목이 중요한 이유는, 많은 사람들이 로컬 추론 최적화를 논할 때 “연산과 I/O를 오버랩하면 되지 않나?”를 먼저 떠올리기 때문입니다.
Flash‑MoE는 ‘가능하면 오버랩’이 아니라, “이 하드웨어에서는 오버랩이 독이 될 수 있다”는 경험을 실험으로 보여줍니다.
7) 실제로 무엇이 들어있나: ‘완제품’에 가까운 C/Metal 추론 엔진
프로젝트 구조를 보면 단순 데모가 아니라 “진짜 엔진” 쪽에 가깝습니다.
metal_infer/infer.m: 추론 엔진(대략 7천 라인 수준이라고 설명)shaders.metal: Metal 커널chat.m: tool calling까지 포함한 인터랙티브 TUItokenizer.h: C BPE 토크나이저(싱글 헤더)
즉, 파이썬/프레임워크를 “안 쓴” 정도가 아니라, 로컬 추론을 위해 필요한 레이어를 상당히 직접 구현하고 엮었습니다.
8) (내 관점) Flash‑MoE가 재미있는 이유: ‘성능’보다 ‘설계 판단의 일관성’
Flash‑MoE가 눈에 띄는 건 단순히 “4.4 tok/s” 같은 숫자 때문이 아닙니다.
오히려 다음 같은 판단들이 일관되게 이어집니다.
- MoE의 본질(K‑of‑N)을 이용해 디스크 스트리밍을 정면으로 선택
- 복잡한 캐시/예측을 만들지 않고 OS 페이지 캐시에 위임
- 통합 메모리의 특성상 I/O와 GPU 오버랩이 비효율일 수 있음을 인정
- 2‑bit의 “더 빠름”보다 4‑bit의 “도구 호출이 되는 안정성”을 프로덕션 기준으로 채택
- 결국 성능은 핫 루프(디퀀트 커널)를 수식 단위로 갈아 넣어 확보
이건 ‘최고로 빠른 추론’의 이야기라기보다, “로컬에서 거대한 모델을 현실적으로 굴리려면 어떤 타협이 필요한가”에 대한 훌륭한 사례입니다.
9) 빠르게 만져보기(README 요약)
아래는 저장소에 적힌 Quick Start를 그대로 요약한 것입니다.
cd metal_infer
make
# 4-bit inference (packed_experts/ 디렉터리 필요)
./infer --prompt "Explain quantum computing" --tokens 100
# 2-bit (더 빠르지만 tool calling이 깨질 수 있음)
./infer --prompt "Explain quantum computing" --tokens 100 --2bit
# tool calling 포함 대화형
./chat주의할 점은, ‘엔진’만으로 끝나지 않고 실제로 모델 가중치 준비/패킹(packed_experts/) 과정이 필요하다는 겁니다. (로컬에서 재현하려면 가장 먼저 부딪히는 지점일 가능성이 큽니다.)
마치며: Flash‑MoE는 “온디바이스의 끝”이 아니라 “온디바이스의 시작”에 가깝다
Flash‑MoE는 많은 사람들이 막연히 “될 리 없지”라고 생각했던 영역을, 아주 구체적인 선택들로 ‘되는 형태’로 만들었습니다.
특히, 애플 실리콘/통합 메모리/Metal이라는 환경에서
- “무조건 겹쳐라(오버랩)”
- “내가 캐시를 더 똑똑하게 만들면 된다”
같은 접근이 반드시 정답이 아닐 수 있다는 걸 보여준 점이 인상적입니다.
로컬 추론이 점점 ‘제품’으로 가까워지는 시점에, 이런 프로젝트는 “성능 숫자”보다 “설계의 감각” 자체가 레퍼런스가 됩니다.
{kind=link}