DeepSeek-TUI는 겉으로 보면 단순한 터미널용 TUI다. 하지만 README를 끝까지 읽어보면 이야기가 달라진다. 이 프로젝트는 채팅 인터페이스가 아니라, DeepSeek V4를 기준으로 한 작업 런타임에 가깝다. 파일을 읽고, 쉘을 실행하고, git을 만지고, web/MCP를 붙이고, 필요하면 서브 에이전트까지 돌린다.
요약하면 이렇다.
- 모델을 고르는 도구가 아니라 작업 흐름을 담는 셸이다.
- 단순 프롬프트 실행기가 아니라 approval gate가 있는 코딩 에이전트다.
- UI가 아니라 터미널 안의 운영면이다.
며칠 전 GitHub Trending에 잠깐 등장한 이유도 여기 있다. 사람들은 모델 자체보다, 모델을 실제 작업으로 바꾸는 표면에 반응한다.
1. DeepSeek-TUI가 겨냥하는 문제
AI 코딩 도구를 써보면 금방 느끼는 불편함이 있다. 같은 질문을 해도 결과가 매번 다르고, 세션이 길어질수록 맥락이 지저분해지고, 중요한 작업도 사람이 계속 개입해야 한다. 결국 에이전트는 편한데 운영은 불안정해진다.
DeepSeek-TUI는 이 문제를 터미널 쪽에서 풀려고 한다. README 기준으로 이 프로젝트는 다음을 전부 한 덩어리로 묶는다.
- 파일 읽기/수정
- shell 실행
- git 작업
- web search / browse
- apply-patch
- sub-agents
- MCP 서버 연결
- LSP diagnostics
- session save/resume
- durable task queue
즉, DeepSeek-TUI의 핵심은 “대화를 잘하는 앱”이 아니라 터미널 작업을 에이전트형으로 재구성한 실행 환경이다.
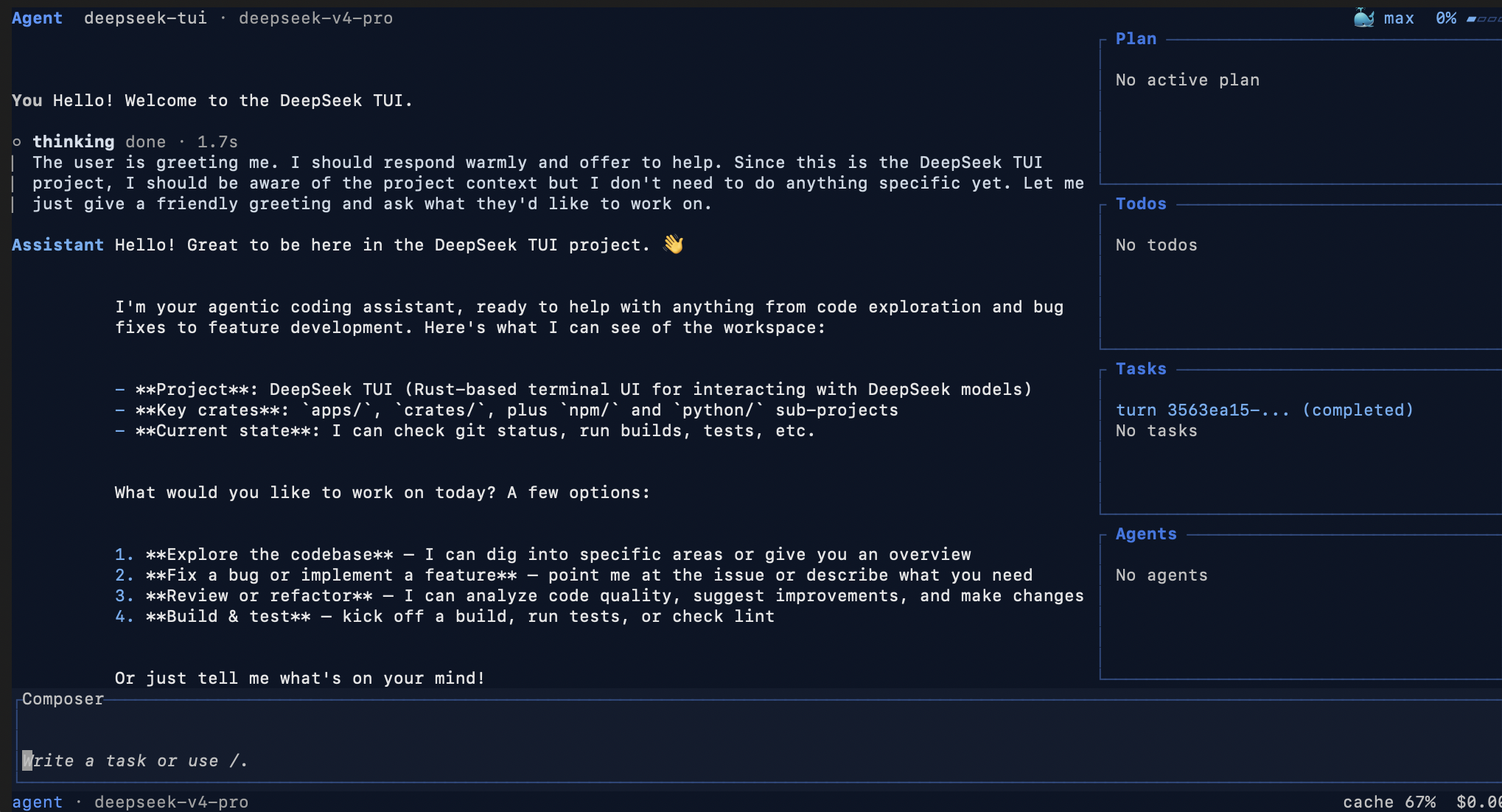
2. 가장 중요한 기능은 auto다
이 프로젝트에서 가장 눈에 띄는 기능은 의외로 화려한 UI가 아니다. 저는 --model auto가 더 중요하다고 봤다.
README에 따르면 auto mode는 한 번의 turn마다:
- 어떤 모델을 쓸지
- thinking을 어느 수준으로 둘지
를 자동으로 고른다. 선택지는 대체로 deepseek-v4-flash와 deepseek-v4-pro, 그리고 off / high / max thinking 조합이다.
이게 왜 중요하냐면, 많은 도구는 모델 선택을 사용자의 수동 설정으로 남겨둔다. 그런데 실제 작업에서는 매번 같은 강도의 추론이 필요하지 않다. 짧은 질의는 가볍게, 복잡한 디버깅은 무겁게 가는 쪽이 맞다.
DeepSeek-TUI는 여기서 한 걸음 더 나간다. 모델 선택 자체를 runtime policy로 만든다.
이건 단순 편의 기능이 아니다. 에이전트 운영에서는 “무슨 모델이 좋은가”보다 “언제 비싼 추론을 쓸 것인가”가 더 중요해지는 순간이 온다. auto는 그 결정을 사용자가 매번 손으로 하지 않게 만든다.
3. 이 프로젝트의 구조는 셸 + 에이전트 + 정책 엔진에 가깝다
README를 기준으로 보면 DeepSeek-TUI는 다음 3층으로 이해하는 게 제일 쉽다.

1) 인터페이스 층
사용자는 deepseek 명령으로 들어온다. 여기서 중요한 건 명령형 인터페이스라는 점이다. 대화창이 아니라 작업 진입점이다.
2) 실행 층
실행 층은 파일, shell, git, web, MCP, sub-agent를 다룬다. 즉, 에이전트가 “말만 하는 상태”에 머물지 않게 한다. 이 계층이 있어야 실제로 코드를 바꾸고 검증할 수 있다.
3) 정책 층
auto routing, approval gate, thinking level, cost accounting이 여기 들어간다. 이 층이 없으면 코딩 에이전트는 금방 즉흥적이 된다. DeepSeek-TUI는 이걸 꽤 명시적으로 다룬다.
제가 보기엔 이 조합이 프로젝트의 정체성을 만든다. LLM을 UI에 붙인 것이 아니라, UI를 포함한 작업 시스템을 만든 것이다.
4. 기술적으로 눈여겨볼 부분
Streaming reasoning blocks
DeepSeek-TUI는 reasoning block을 스트리밍한다. 이건 단순히 “생각 과정을 보여준다” 수준이 아니다. 긴 작업을 할 때 사용자가 현재 어디까지 왔는지 판단하는 신호가 된다.
Worktree 기반 rollback
README에는 workspace rollback과 side-git snapshot이 나온다. 이건 실무에서 꽤 중요하다.
- 메인 브랜치를 덜 더럽힌다
- 실험과 본작업을 분리한다
- 되돌리기가 쉽다
AI 코딩 도구가 실전에서 무너지는 이유 중 하나는, 실패보다 되돌리기 비용이 더 크기 때문이다. 이 프로젝트는 그 비용을 낮추는 쪽에 투자했다.
MCP와 LSP
MCP 서버 연결과 LSP diagnostics를 같이 넣은 것도 좋다. 보통 에이전트는 “무언가를 만들 수 있는가”에 집중하고, “만든 뒤 검증할 수 있는가”는 약하다. DeepSeek-TUI는 그 둘을 붙여서 에이전트의 출력을 더 빨리 검증 가능한 상태로 만든다.
Durable task queue와 session resume
장기 작업을 다루는 사람에게는 이 부분이 중요하다.
- 세션 저장/재개
- 백그라운드 태스크
- 이어서 하기
이 조합이 있어야 “한 번 열고 끝”이 아니라, 하루 종일 쓰는 도구가 된다.
5. 왜 Claude Code류와 다른 느낌이 드나
비슷한 도구는 많다. 하지만 DeepSeek-TUI는 성격이 조금 다르다.
- Claude Code가 범용성 높은 코딩 에이전트 경험에 강하다면
- DeepSeek-TUI는 DeepSeek V4에 맞춘 터미널 운영체계에 더 가깝다
차이는 세부 기능보다 철학에서 나온다.
- 더 넓은 모델 생태계보다 DeepSeek 중심 최적화를 택한다
- 웹 UI보다 터미널 중심 흐름을 택한다
- 단순 자동화보다 approval gate와 rollback을 택한다
- 비동기 chat보다 작업 단위와 session continuity를 택한다
그래서 이 도구는 “아무나 바로 쓰는 보편적 에이전트”라기보다, 터미널에서 작업하는 사람에게 맞춘 강한 의견의 도구로 보인다.
6. 지금 시점의 프로젝트 상태도 꽤 활발하다
GitHub API 기준으로 이 저장소는 현재 다음 상태다.
- Stars: 12,789
- Forks: 967
- Open issues: 217
- 언어: Rust
- 최신 릴리스:
v0.8.14— 2026-05-06 01:23 UTC
리포지토리 설명도 분명하다. “Coding agent for DeepSeek models that runs in your terminal.”
즉, 이건 실험용 데모가 아니라 지금도 빠르게 다듬어지는 실사용 도구다. 릴리스 주기도 촘촘해서 최근에도 안정화 작업이 계속 들어가고 있다.
다만 활발함과 완성도는 같은 말이 아니다. 오픈 이슈가 200개가 넘는다는 건 기능이 많고 변화 속도가 빠르다는 뜻이기도 하다. 실제 도입 시에는 최신 릴리스와 이슈를 같이 보는 게 맞다.
7. 이 프로젝트가 잘 맞는 사람
DeepSeek-TUI는 아래 사용자에게 특히 잘 맞는다.
- 터미널 작업 비중이 높은 사람
- DeepSeek API를 이미 쓰고 있는 사람
- 코딩 에이전트를 “대화 도구”보다 “작업 시스템”으로 보는 사람
- worktree, rollback, MCP, LSP 같은 운영 디테일을 중요하게 보는 사람
- 중국권/미러 환경까지 고려한 설치 유연성이 필요한 사람
반대로 이런 경우엔 덜 맞을 수 있다.
- GUI 기반 경험을 더 선호하는 사람
- 모델 다양성을 최우선으로 보는 사람
- 터미널 중심 워크플로우가 없는 사람
- DeepSeek API key를 쓰기 싫은 사람
결국 이 프로젝트는 범용 정답이 아니라, 터미널을 주 작업면으로 쓰는 사람에게 강하게 맞는 선택지다.
8. 한 줄 결론
DeepSeek-TUI는 “DeepSeek를 터미널에서 쓸 수 있는 앱”이 아니다. 더 정확히 말하면, DeepSeek V4를 중심으로 한 코딩 에이전트 운영체계다.
모델 경쟁이 비슷해질수록, 승부는 결국 실행면과 정책, 그리고 되돌릴 수 있는 구조에서 난다. 이 프로젝트는 그 방향을 꽤 분명하게 보여준다.