Agent Harness Engineering: A Survey는 좋은 서베이지만, 한 번에 읽기 쉬운 글은 아니다. 170개가 넘는 프로젝트, 7계층 분류, 긴 오픈 프라블럼 목록이 한데 묶여 있어서, 본문만 덤벼들면 금방 길을 잃는다. 그래서 이 주제는 “논문을 읽는 법”과 “논문을 제대로 쓰게 해주는 자료를 찾는 법”을 분리해서 봐야 한다.
이 글은 서베이 본문을 다시 요약하기보다, 서베이를 실제로 학습하는 데 필요한 리소스 맵을 정리한다. 즉, 무엇을 먼저 보고, 무엇을 나중에 보고, 어디서 사례를 확장할지에 대한 실전 안내서다.
왜 리소스 맵이 따로 필요한가
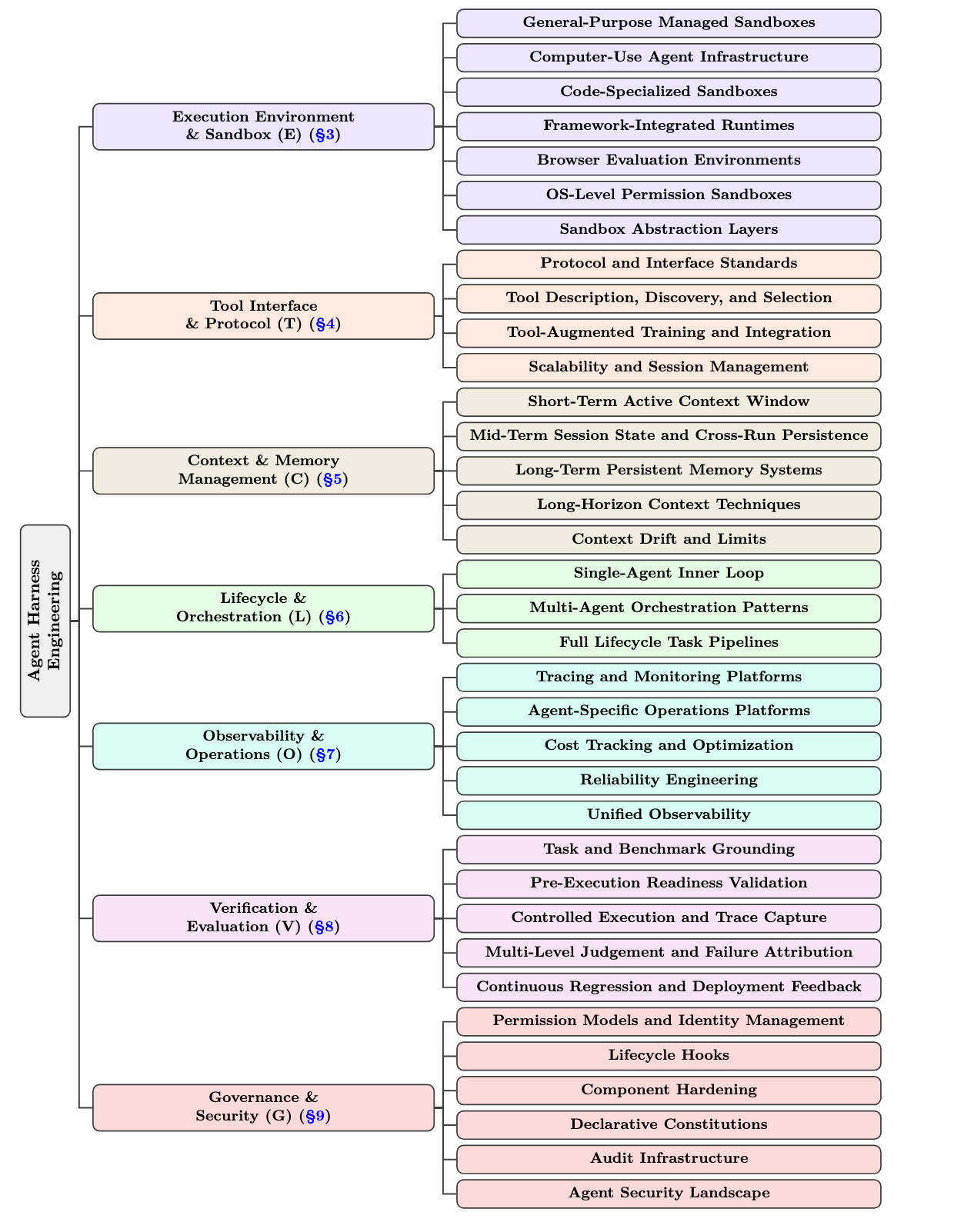
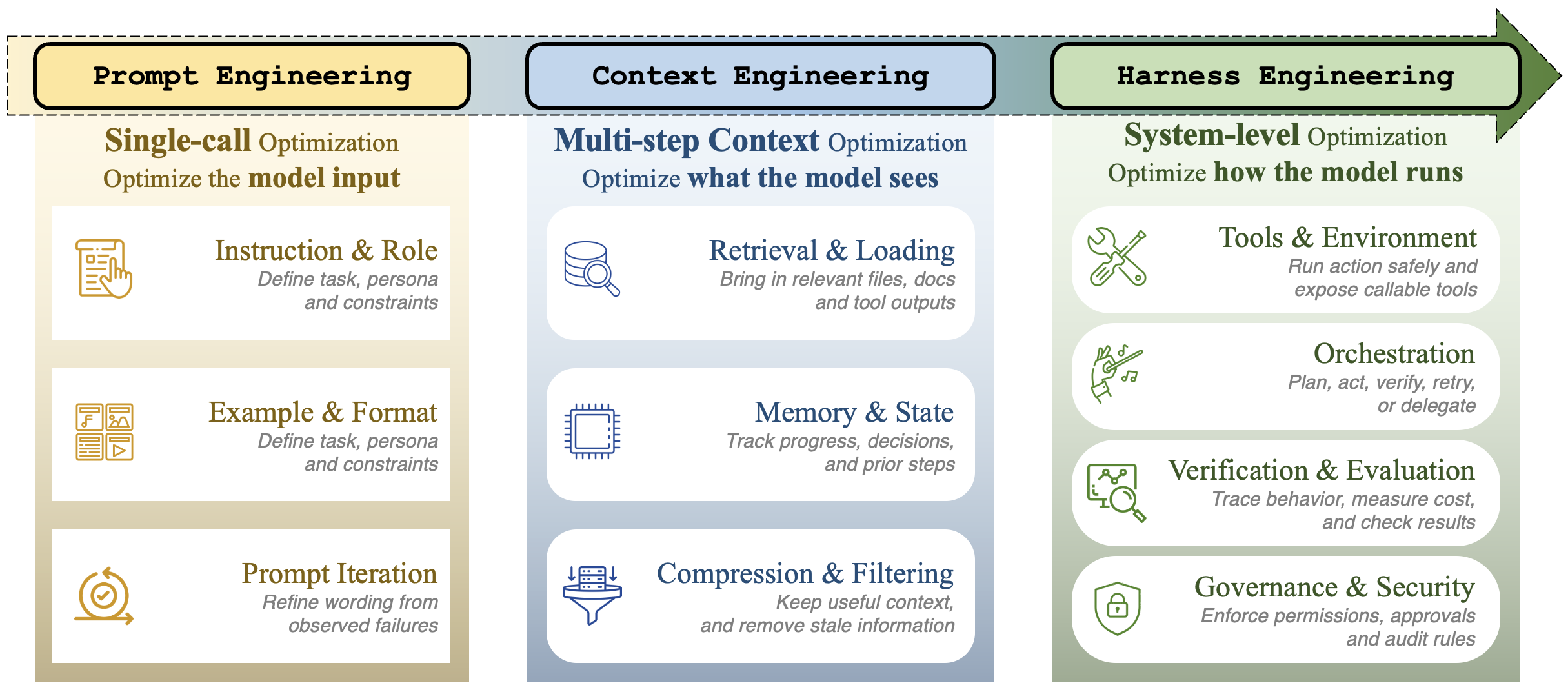
하네스 엔지니어링은 단순한 프롬프트 튜닝이 아니다. 실행 환경(E), 도구 계약(T), 컨텍스트(C), 라이프사이클(L), 관측(O), 검증(V), 거버넌스(G)까지 한 번에 다룬다. 문제는 이 계층들이 서로 얽혀 있어서, 어느 자료를 먼저 읽느냐에 따라 이해 속도가 크게 달라진다는 점이다.
서베이의 공식 프로젝트 페이지는 이 지도를 한 장으로 요약하고, PDF는 그 지도의 근거를 설명한다. 반면 awesome-agent-harness는 그 지도가 실제로 가리키는 오픈소스 생태계를 보여준다. 둘의 역할이 다르다. 하나는 개념 지도, 다른 하나는 현장 지도다.
한눈에 보는 자료 역할
| 자원 | 역할 | 먼저 뽑아야 할 것 |
|---|---|---|
| 프로젝트 페이지 | 핵심 다이어그램과 요약 | ETCLOVG 전체 구조 |
| OpenReview PDF | 정식 본문 | 정의, 주장, open problems |
| awesome-agent-harness | 살아 있는 카탈로그 | 카테고리별 실제 프로젝트 |
| Hugging Face 데이터셋 | 분류와 재분석의 재료 | 라벨링, 재현성, 추가 분석 |
| NotebookLM 노트북 | 질문형 학습 | 특정 질문에 대한 빠른 추적 |
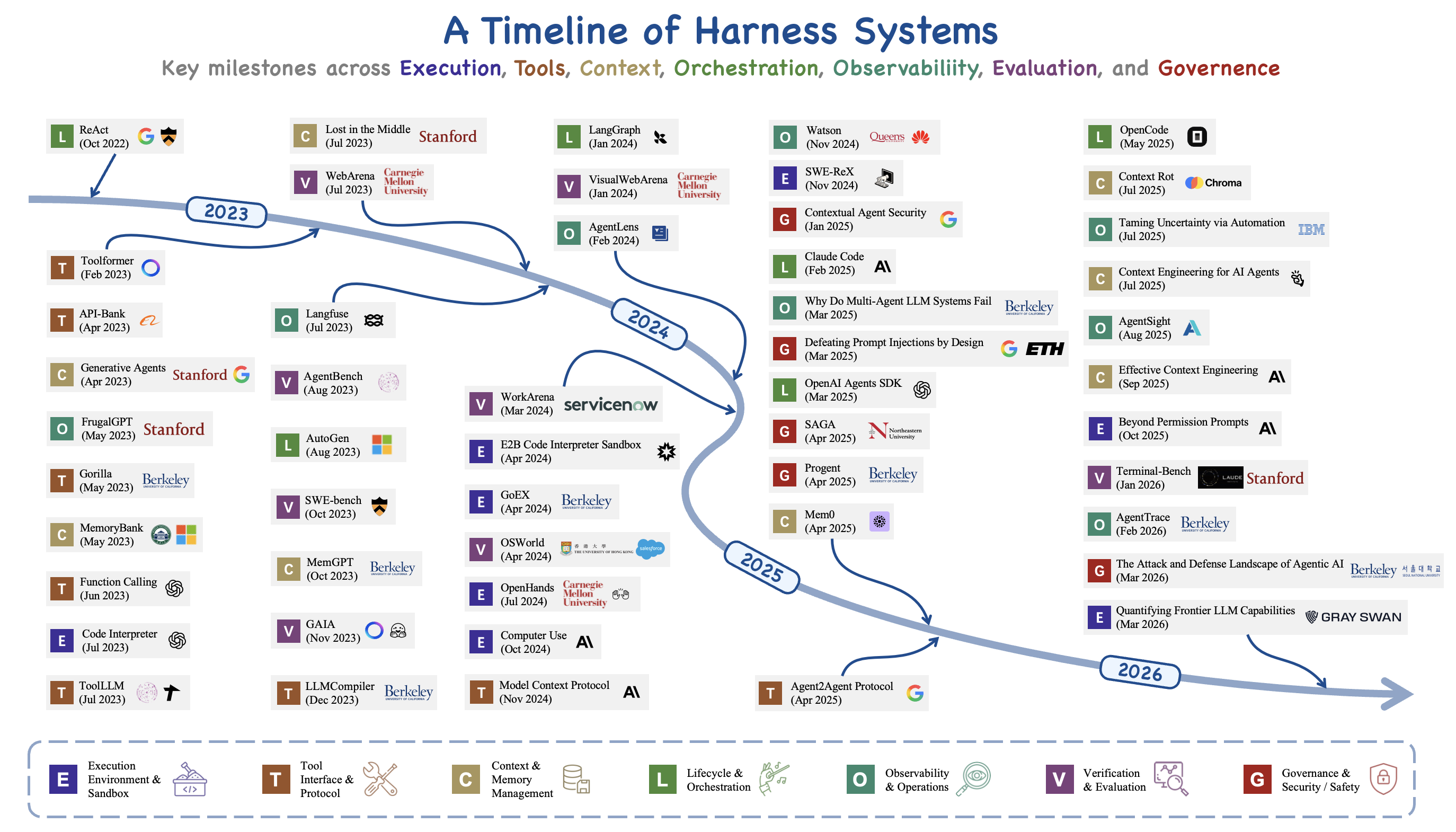
특히 awesome-agent-harness는 단순 링크 모음이 아니다. 2026-05-25 기준으로 207개 항목, 9개 카테고리, 87.9% GitHub-backed인 살아 있는 목록이다. 즉, 서베이가 말하는 “하네스”가 논문 안에서만 머무는 게 아니라, 실제 저장소와 도구와 벤치마크로 번져 있다는 걸 확인하게 해준다.
ETCLOVG를 읽는 순서
ETCLOVG는 단순한 분류명이 아니다. 읽는 순서까지 암시한다. 모든 레이어를 동시에 붙잡으려 하면 금방 과부하가 온다. 그래서 목적별로 끊어 읽는 게 좋다.
1) 빌더라면 E / T / L부터
에이전트를 직접 만들고 있다면 먼저 이 세 계층을 본다.
- E — Execution environment: 컨테이너, microVM, 브라우저, 데스크톱 VM 같은 실행 경계
- T — Tool interface & protocol: MCP, A2A, function calling, tool schema
- L — Lifecycle & orchestration: 루프, task pipeline, 멀티에이전트 흐름
이 세 개는 “에이전트가 어디서, 무엇과, 어떤 순서로 움직이는가”를 결정한다. 모델이 좋아져도 여기서 막히면 전체 시스템은 무너진다.
2) 운영한다면 O / G를 따로 봐야 한다
프로토타입에서는 잘 안 보이지만, 운영 단계에서는 이 두 개가 핵심이다.
- O — Observability & operations: tracing, cost, latency, failure diagnosis
- G — Governance & security: 권한, 정책, 감사, 안전장치
서베이가 흥미로운 이유는 이 둘을 “부속품”이 아니라 별도 레이어로 올려놓았기 때문이다. 실제 현장에서는 가장 늦게 성숙하지만, 한 번 사고가 나면 가장 먼저 드러나는 것도 이쪽이다.
3) 평가한다면 V를 모델보다 앞에 놓아야 한다
- V — Verification & evaluation: benchmark, regression feedback, trace capture
하네스가 잘 작동하는지 판단하려면 outcome만 보면 부족하다. 어떤 trajectory를 거쳤는지, 실패가 어디서 났는지, 변경이 다른 레이어와 충돌했는지를 함께 봐야 한다. 그래서 서베이의 평가 관점은 단순 점수표보다 훨씬 실용적이다.
4) 메모리는 C에서 끝나지 않는다
- C — Context & memory management: retrieval, compaction, long-term memory
컨텍스트는 많을수록 좋은 게 아니다. 중요한 건 무엇을 남기고 무엇을 버릴지다. 하네스 관점에서 메모리는 기능이 아니라 상태 관리 정책이다.
1시간 / 1일 / Q&A로 읽는 법
이 자료 묶음의 장점은 독서 시간을 쪼개기 쉽다는 점이다.
1시간 컷
- 프로젝트 페이지의 한 장 요약을 본다.
- ETCLOVG 그림만 먼저 훑는다.
awesome-agent-harness에서 각 카테고리별 상위 3개씩만 찍어본다.
이 정도만 해도 “하네스가 어디까지 확장됐는지” 감이 온다.
하루 컷
- OpenReview PDF를 통독한다.
awesome-agent-harness에서 카테고리별 대표 프로젝트를 더 깊게 본다.- 관심 레이어(E/T/L/O/G/V/C)를 하나 정해 실제 레포를 따라간다.
하루 단위로 읽으면, 논문이 말하는 개념과 생태계의 실제 모습이 맞물린다.
Q&A 컷
질문이 많은 사람이라면 NotebookLM 같은 대화형 독서 방식이 잘 맞는다.
- ETCLOVG와 기존 6-component framework의 차이는 무엇인가?
- O와 G가 왜 별도 레이어로 승격됐는가?
- “하네스 결합 문제”는 실제로 어떤 변경에서 발생하는가?
- open problems 중 지금 당장 제품화에 가장 가까운 것은 무엇인가?
이런 질문은 PDF를 단순 검색하는 것보다, 문맥을 유지한 채 되묻는 방식이 훨씬 잘 맞는다.
이 리소스 맵이 드러내는 것
리소스 맵을 따로 정리해 보면, 서베이의 진짜 메시지가 더 선명해진다. 핵심은 “하네스가 중요하다”가 아니라, 하네스는 이제 독립적인 시스템 계층으로 읽어야 한다는 점이다.
그 말은 곧, 다음과 같은 변화가 필요하다는 뜻이기도 하다.
- 모델 비교보다 실행 환경 비교를 먼저 하라.
- 기능 목록보다 도구 계약을 먼저 보라.
- 결과 점수보다 트레이스와 실패 원인을 남겨라.
- 개별 스크립트보다 플랫폼과 운영 정책을 설계하라.
이 관점에서 보면 awesome-agent-harness는 부록이 아니다. 서베이가 말하는 분류를 실제 프로젝트와 연결해 주는, 가장 실용적인 입구다.
마치며
Agent Harness Engineering 서베이는 “에이전트는 모델만으로 설명되지 않는다”는 사실을 체계적으로 정리한 문서다. 하지만 그 문서를 읽는 데 필요한 자료까지 함께 봐야 비로소 의미가 살아난다.
프로젝트 페이지는 지도를 주고, PDF는 논리를 주고, awesome list는 현장을 보여주고, 데이터셋은 재분석의 가능성을 연다. 이 네 가지를 함께 놓으면, ETCLOVG는 더 이상 추상적인 약어가 아니라 실제로 따라갈 수 있는 학습 경로가 된다.