
매일 아침 Claude Code를 열면 똑같은 일이 반복된다. “우리 프로젝트는 JWT 인증을 jose로 구현했고, 테스트는 test/auth.test.ts에, Edge 호환성 때문에 jsonwebtoken 대신 jose를 선택했어.” 세션이 끝나면 모든 컨텍스트가 증발하고, 다음 날 다시 설명해야 한다.
rohitg00/agentmemory는 이 문제를 근본적으로 해결한다. 에이전트가 도구를 사용할 때마다 조용히 관찰을 기록하고, 세션이 끝나면 압축하여 구조화된 기억으로 저장하며, 다음 세션 시작 시 필요한 컨텍스트만 정확히 주입한다. 4,400개 이상의 GitHub 스타와 400개 이상의 포크가 증명하듯, 이건 단순한 아이디어가 아니라 이미 검증된 솔루션이다.
1. 왜 지금 이 문제가 중요한가
AI 코딩 에이전트 생태계는 빠르게 성장하고 있지만, 기억은 여전히 가장 취약한 지점이다. Claude Code의 MEMORY.md, Cursor의 notepads, Cline의 memory bank — 모두 정적 텍스트 파일에 불과하다.
| 내장 메모리 (CLAUDE.md) | agentmemory | |
|---|---|---|
| 규모 | 200줄 제한 | 무제한 |
| 검색 | 전체 컨텍스트 로드 | BM25 + 벡터 + 그래프 (top-K) |
| 토큰 비용 | 240개 관찰 시 22K+ 토큰 | ~1,900 토큰 (92% 절감) |
| 에이전트 간 공유 | 파일 단위 | MCP + REST (모든 에이전트) |
| 가시성 | 수동 파일 읽기 | 실시간 뷰어 (:3113) |
CLAUDE.md에 모든 내용을 담을 수 없는 이유는 간단하다. 200줄로는 컨텍스트 윈도우 낭비와 정보 부족 사이에서 줄타기할 수밖에 없다. agentmemory는 필요한 것만 검색해서 주입하므로, 92% 적은 토큰으로 더 정확한 컨텍스트를 제공한다.
2. 핵심 아키텍처: 4계층 기억 통합
agentmemory는 인간 두뇌의 기억 처리 방식을 모방한 4계층 구조를 채택했다.
| 계층 | 설명 | 비유 |
|---|---|---|
| Working | 도구 사용의 원시 관찰 | 단기 기억 |
| Episodic | 압축된 세션 요약 | ”무슨 일이 있었는지” |
| Semantic | 추출된 사실과 패턴 | ”내가 아는 것” |
| Procedural | 워크플로우와 결정 패턴 | ”어떻게 하는지” |
기억은 시간에 따라 자연스럽게 감쇠(Ebbinghaus 곡선)하고, 자주 접근하는 기억은 강화되며, 오래된 기억은 자동으로 제거된다. 모순이 감지되면 해결 로직이 작동한다.
메모리 파이프라인
PostToolUse 후크 발동
→ SHA-256 중복 제거 (5분 윈도우)
→ 프라이버시 필터 (시크릿, API 키 제거)
→ 원시 관찰 저장
→ LLM 압축 → 구조화된 사실 + 개념 + 내러티브
→ 벡터 임베딩 (6개 제공자 + 로컬)
→ BM25 + 벡터 인덱싱
Stop / SessionEnd 후크 발동
→ 세션 요약
→ 지식 그래프 추출
→ 슬롯 리플렉션
SessionStart 후크 발동
→ 프로젝트 프로필 로드
→ 하이브리드 검색 (BM25 + 벡터 + 그래프)
→ 토큰 버짓 적용 (기본 2,000 토큰)
→ 대화에 주입특히 주목할 점은 완전 자동화다. 12개의 후크가 모든 도구 사용을 자동으로 캡처하므로, 사용자가 수동으로 add()를 호출할 필요가 전혀 없다. 이것이 mem0(53K ⭐)과의 결정적 차이다.
3. 검색: BM25 + 벡터 + 그래프의 삼중 융합
agentmemory의 검색은 단순한 벡터 유사도가 아니다. 세 가지 신호를 RRF(Reciprocal Rank Fusion, k=60)로 융합한다.
| 스트림 | 역할 | 활성 조건 |
|---|---|---|
| BM25 | 스테밍 키워드 매칭 + 동의어 확장 | 항상 활성 |
| Vector | 코사인 유사도 기반 밀집 임베딩 검색 | 임베딩 제공자 설정 시 |
| Graph | 지식 그래프 엔티티 매칭 + BFS 탐색 | 쿼리에서 엔티티 감지 시 |
임베딩은 all-MiniLM-L6-v2 기반 로컬 모델을 권장한다. 오프라인에서 작동하고, BM25-only 대비 +8pp 재현율 향상을 제공하며, API 키도 필요 없다. 필요하다면 Gemini, OpenAI, Voyage AI, Cohere, OpenRouter도 지원한다.
실제 벤치마크 결과가 인상적이다:
| 시스템 | R@5 | R@10 | MRR |
|---|---|---|---|
| agentmemory | 95.2% | 98.6% | 88.2% |
| BM25-only | 86.2% | 94.6% | 71.5% |
LongMemEval-S(ICLR 2025) 벤치마크에서 95.2% R@5를 기록했다. mem0의 68.5%(LoCoMo), Letta의 83.2%(LoCoMo)와 비교하면 거의 10%p 이상 차이다.
4. 51개 MCP 도구: 기억을 넘어선 오케스트레이션
agentmemory는 단순한 기억 저장소가 아니다. 51개의 MCP 도구(선택적 확장), 6개 리소스, 3개 프롬프트, 4개 스킬을 제공하는 완전한 에이전트 메모리 플랫폼이다.
핵심 도구만 해도 memory_smart_search, memory_save, memory_sessions, memory_file_history, memory_profile 등 11개다. 확장 도구를 활성화하면 멀티 에이전트를 위한 memory_lease(배타적 작업 임대), memory_signal_send(에이전트 간 메시징), memory_mesh_sync(P2P 동기화)까지 사용할 수 있다.
모든 주요 코딩 에이전트를 지원한다는 점도 강점이다:
- Claude Code: 12개 후크 + MCP + 스킬
- Cursor, Gemini CLI, Codex CLI: MCP 서버
- OpenClaw, Hermes Agent: MCP + 전용 플러그인
- Aider: REST API
- 그 외 32개 이상 에이전트:
npx skillkit install agentmemory
하나의 메모리 서버가 모든 에이전트와 세션에서 공유된다. Claude Code로 작업하다가 Cursor로 전환해도 같은 기억에 접근할 수 있다.
5. 경쟁 제품과의 비교
| agentmemory | mem0 | Letta/MemGPT | 내장 메모리 | |
|---|---|---|---|---|
| 유형 | 메모리 엔진 + MCP | 메모리 레이어 API | 완전한 에이전트 런타임 | 정적 파일 |
| 자동 캡처 | 12개 후크 (제로 수동) | 수동 add() 호출 | 에이전트 자체 편집 | 수동 편집 |
| 검색 | BM25+벡터+그래프(RRF) | 벡터+그래프 | 벡터(아카이브) | 전체 로드 |
| 멀티 에이전트 | MCP+REST+리스+시그널 | API (조정 없음) | Letta 런타임 내 | 에이전트별 파일 |
| 외부 의존성 | 없음 (SQLite+iii) | Qdrant/pgvector | Postgres+벡터DB | 없음 |
| 기억 생애주기 | 4계층 통합+감쇠+자동 삭제 | 수동 추출 | 에이전트 관리 | 수동 정리 |
agentmemory의 가장 큰 차별점은 프레임워크 종속성이 없다는 것이다. MCP 프로토콜만 지원하면 어떤 에이전트든 붙일 수 있다. 반면 Letta는 자체 런타임 안에서만 동작하고, mem0은 API는 개방적이지만 자동 캡처 기능이 없다.
6. iii 엔진: 단 세 가지 프리미티브로 구현된 전체 스택
agentmemory의 기술적 백본은 iii 엔진이다. 흥미로운 점은 agentmemory가 단 세 가지 프리미티브(Functions, Triggers, State) 위에 전체 스택을 구축했다는 사실이다.
전통적 스택 → agentmemory가 사용하는 것
Express.js / Fastify → iii HTTP Triggers
SQLite + pgvector → iii KV State + 인메모리 벡터 인덱스
SSE / Socket.io → iii Streams (WebSocket)
pm2 / systemd → iii 엔진 워커 감독
Prometheus / Grafana → iii OTEL + 상태 모니터
커스텀 플러그인 시스템 → iii worker add <name>118개 소스 파일, ~21,800 LOC, 800개 테스트, 123개 함수, 34개 KV 스코프 — 이 모든 것이 단일 iii 인스턴스 위에서 실행된다. Postgres도, Redis도, Express도, pm2도, Prometheus도 필요 없다.
이 구조의 실용적 장점은 확장성이다. iii worker add iii-pubsub 한 줄로 멀티 인스턴스 메모리 동기화를 추가할 수 있고, iii worker add iii-sandbox로 회수된 코드를 격리된 마이크로VM에서 실행할 수 있다.
7. 실시간 가시성: 뷰어와 iii 콘솔
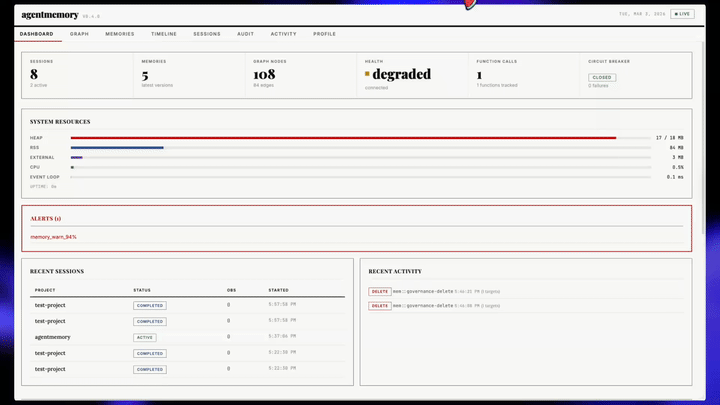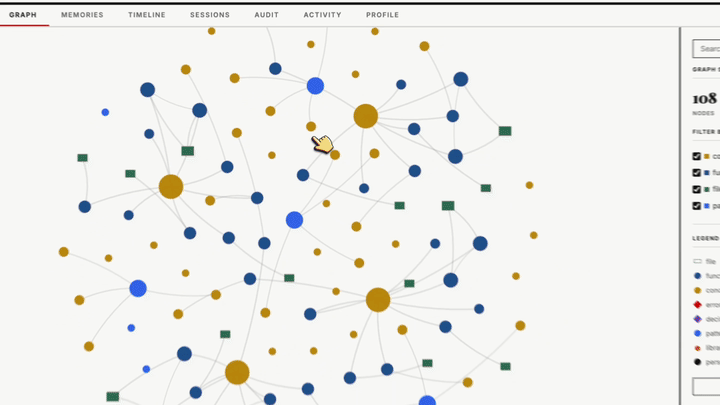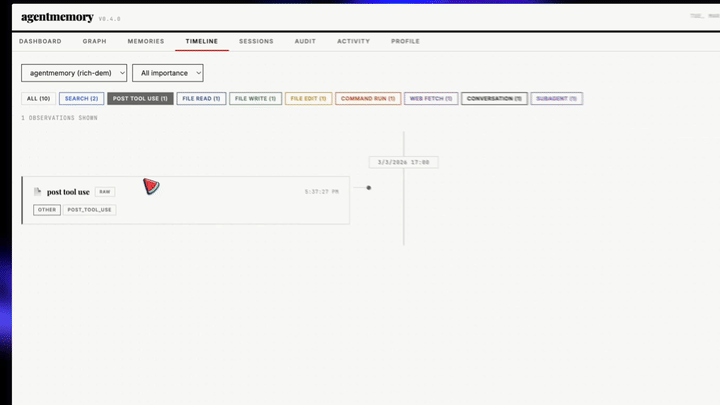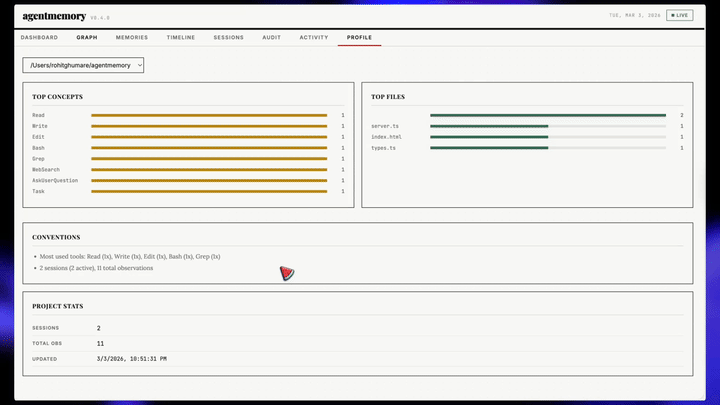
agentmemory는 :3113 포트에 실시간 뷰어를 제공한다. 라이브 관찰 스트림, 세션 탐색기, 메모리 브라우저, 지식 그래프 시각화, 상태 대시보드까지 — 에이전트가 무엇을 기억하고 있는지 투명하게 볼 수 있다.
여기에 iii 콘솔을 추가하면 에이전트가 한 모든 일을 OpenTelemetry 트레이스로 추적할 수 있다. memory_smart_search 하나가 BM25 스캔 → 임베딩 조회 → RRF 융합 → 리랭커로 이어지는 전체 과정을 워터폴 차트로 볼 수 있다.
마치며: 코딩 에이전트의 마지막 퍼즐 조각
AI 코딩 에이전트는 도구 호출, 코드 생성, 멀티 에이전트 협업까지 빠르게 발전해왔다. 하지만 장기 기억만큼은 여전히 풀리지 않은 숙제였다. agentmemory는 이 퍼즐의 마지막 조각을 채워준다.
특히 주목할 점:
- 자동화: 사용자가 아무것도 하지 않아도 12개 후크가 모든 것을 기록한다
- 벤치마크: 95.2% R@5는 실무에서 신뢰할 수 있는 수준이다
- 생태계: Claude Code, Cursor, Hermes, OpenClaw 등 모든 주요 에이전트 지원
- 제로 의존성: SQLite 하나로 모든 것이 작동한다
한 가지 아쉬운 점은 아직 v1.0이 아니라는 것. iii 엔진 버전 핀(v0.11.2)과 윈도우 지원의 거친 부분은 초기 단계의 프로젝트에서 흔히 볼 수 있는 이슈다. 하지만 4,400 스타와 활발한 이슈 대응 속도를 보면 v1.0도 머지않아 보인다.
코딩 에이전트를 진지하게 사용하는 개발자라면, agentmemory는 더 이상 선택이 아닌 필수 도구다.
🔗 관련 정보
- GitHub: https://github.com/rohitg00/agentmemory
- 웹사이트: https://agent-memory.dev
- iii 엔진: https://iii.dev
- 설계 문서 (1050⭐ Gist): https://gist.github.com/rohitg00/2067ab416f7bbe447c1977edaaa681e2
- 벤치마크: LongMemEval-S, 품질, 규모, 비교
- 라이선스: Apache-2.0